

Chọn Mô Hình AI Phù Hợp cho Sử Dụng Cá Nhân trên Thiết Bị Cục Bộ
[!summary] Việc lựa chọn mô hình AI phù hợp để sử dụng trên phần cứng cá nhân đòi hỏi sự cân nhắc kỹ lưỡng về các yếu tố như tài nguyên tính toán, yêu cầu hiệu suất và trường hợp sử dụng cụ thể. Bài viết này sẽ đề cập đến những yếu tố quan trọng khi triển khai mô hình AI trên phần cứng người dùng phổ thông.
Hiểu về Định Dạng GGUF
GGUF (GPT-Generated Unified Format) mang lại nhiều lợi ích khi triển khai cục bộ:
- Thời gian tải nhanh hơn so với các định dạng khác
- Tối ưu hóa đặc biệt cho cấu hình phần cứng người dùng phổ thông
- Tương thích với các framework phổ biến như Unsloth, mang lại hiệu suất ổn định
Ảnh Hưởng của Quantization
Quantization đóng vai trò quan trọng trong việc cân bằng giữa hiệu suất mô hình và mức tiêu thụ tài nguyên:
- Mức quantization thấp hơn (ví dụ: Q4) giúp giảm yêu cầu RAM nhưng có thể ảnh hưởng đến độ chính xác
- Quantization Q4 thường mang lại sự cân bằng tối ưu giữa kích thước mô hình và độ chính xác
- Khi chọn mức quantization, cần xem xét thông số phần cứng và yêu cầu hiệu suất của bạn
Để xác định mức quantization phù hợp với phần cứng của mình, bạn có thể tham khảo công cụ Can I Run This LLM{target="_blank" rel=“noopener noreferrer”}. Công cụ này hỗ trợ tính toán mức quantization tối đa có thể sử dụng trên GPU của Nvidia, AMD và Apple. Visit Example{target="_blank" rel=“noopener noreferrer”}
Cân Nhắc về Kích Thước Mô Hình
Mối quan hệ giữa kích thước mô hình và hiệu suất không đơn giản:
- Các phiên bản quantized thấp của mô hình lớn thường hoạt động tốt hơn các phiên bản quantized cao của mô hình nhỏ hơn
- Đối với các tác vụ viết, các mô hình reasoning lớn (bao gồm cả các phiên bản distilled) cho kết quả tốt hơn với ít lỗi nhiễu (hallucination)
- Với các tác vụ lập luận và giải quyết vấn đề logic, sự khác biệt giữa các kích thước mô hình ít quan trọng hơn
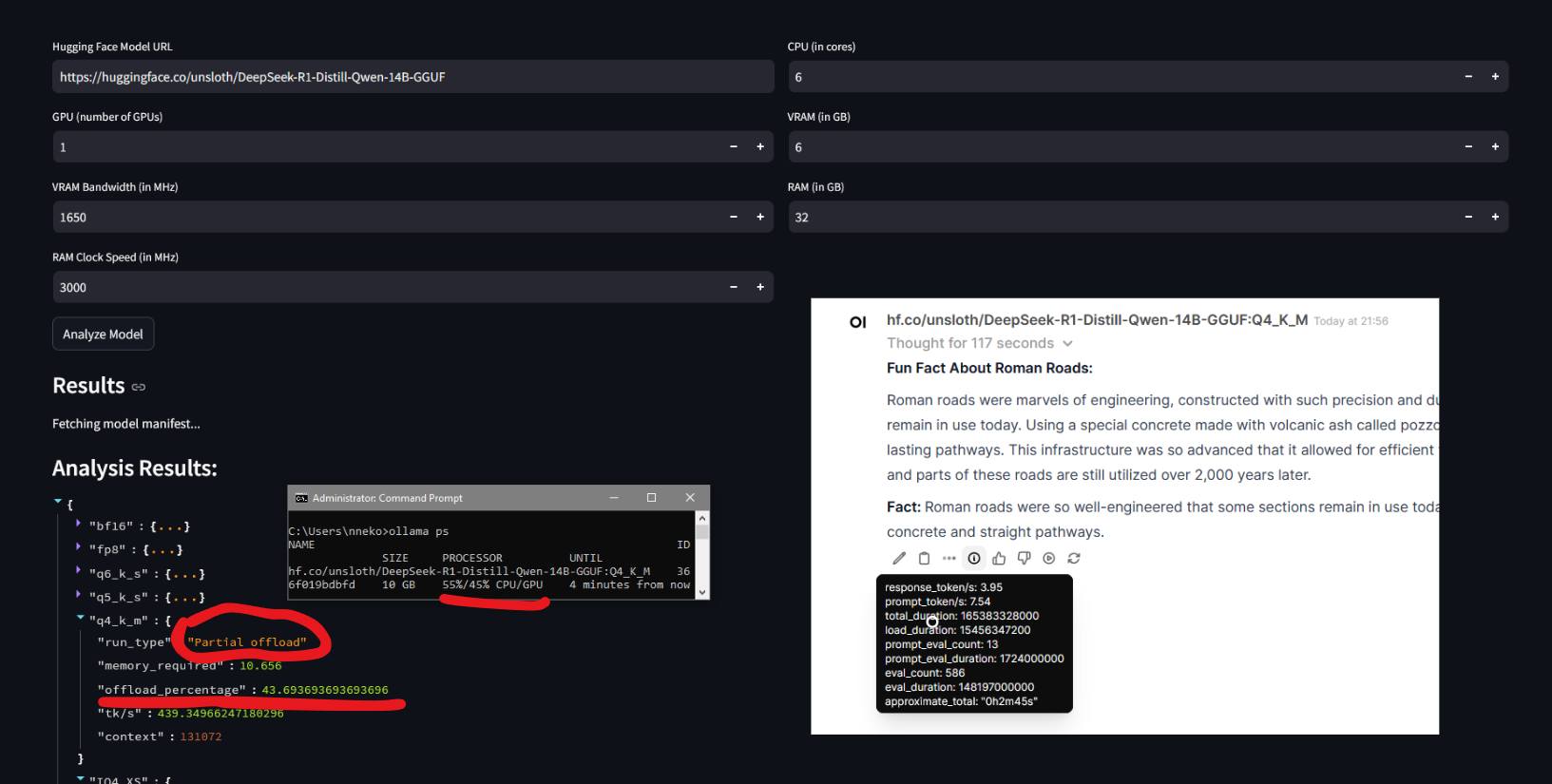
Tối Ưu Hóa Phân Bổ Tài Nguyên Phần Cứng
Việc phân bổ tài nguyên hợp lý có ảnh hưởng lớn đến hiệu suất:
- Chọn các mô hình có thể chạy mà không làm CPU chịu tải quá lớn so với GPU
- Các mô hình có thể chạy hoàn toàn trong VRAM thường mang lại hiệu suất tốt hơn
- Phân bổ tài nguyên hợp lý giúp duy trì tốc độ tạo token hợp lý (tokens per second)
- Mô hình không phù hợp có thể khiến thời gian phản hồi quá lâu (5-10 phút)
Fine-tuning cho Ứng Dụng Chuyên Biệt
Để có hiệu suất tối ưu trong các lĩnh vực cụ thể:
- Cân nhắc sử dụng các mô hình đã fine-tuned cho các ứng dụng chuyên biệt
- Fine-tuning theo từng lĩnh vực có thể cải thiện đáng kể độ chính xác và hiệu suất
- Đánh giá xem hiệu suất tăng có xứng đáng với tài nguyên cần thiết để fine-tune hay không
Kết Luận
Việc chọn mô hình AI phù hợp để triển khai cục bộ cần cân nhắc nhiều yếu tố như định dạng, mức quantization, kích thước mô hình và cách phân bổ tài nguyên phần cứng. Bằng cách xem xét kỹ lưỡng các yếu tố này và sử dụng các công cụ như Can I Run This LLM, người dùng có thể tối ưu hóa hiệu suất mô hình mà vẫn đảm bảo hoạt động trong giới hạn phần cứng sẵn có.
