

Choosing the Right AI Model for Personal Use on Local Devices
[!info] Selecting the right AI model for personal use on local hardware requires careful consideration of various factors including computational resources, performance requirements, and specific use cases. This article explores key considerations when choosing models for deployment on consumer hardware.
Understanding GGUF Format
The GGUF (GPT-Generated Unified Format) offers significant advantages for local deployment:
- Faster loading times compared to alternative formats
- Optimized specifically for consumer hardware configurations
- Compatible with popular frameworks like Unsloth, which delivers reliable performance
The Impact of Quantization
Quantization plays a crucial role in balancing resource utilization and model performance:
- Lower quantization levels (e.g., Q4) reduce RAM requirements but may impact accuracy
- Q4 quantization typically offers an optimal balance between model size and performance accuracy
- When selecting quantization levels, consider your available hardware specifications and performance requirements
For determining the appropriate quantization level based on your specific hardware configuration, Can I Run This LLM provides an excellent resource. This tool helps calculate the maximum quantization level suitable for your hardware, with support for popular Nvidia, AMD, and Apple GPUs.
Model Size Considerations
The relationship between model size and performance is nuanced:
- Lower quantized versions of larger models generally outperform higher quantized versions of smaller models
- For writing tasks, larger reasoning models (including distilled versions) demonstrate better performance with less hallucination
- For reasoning tasks and logical problem solving, the difference between model sizes becomes less significant
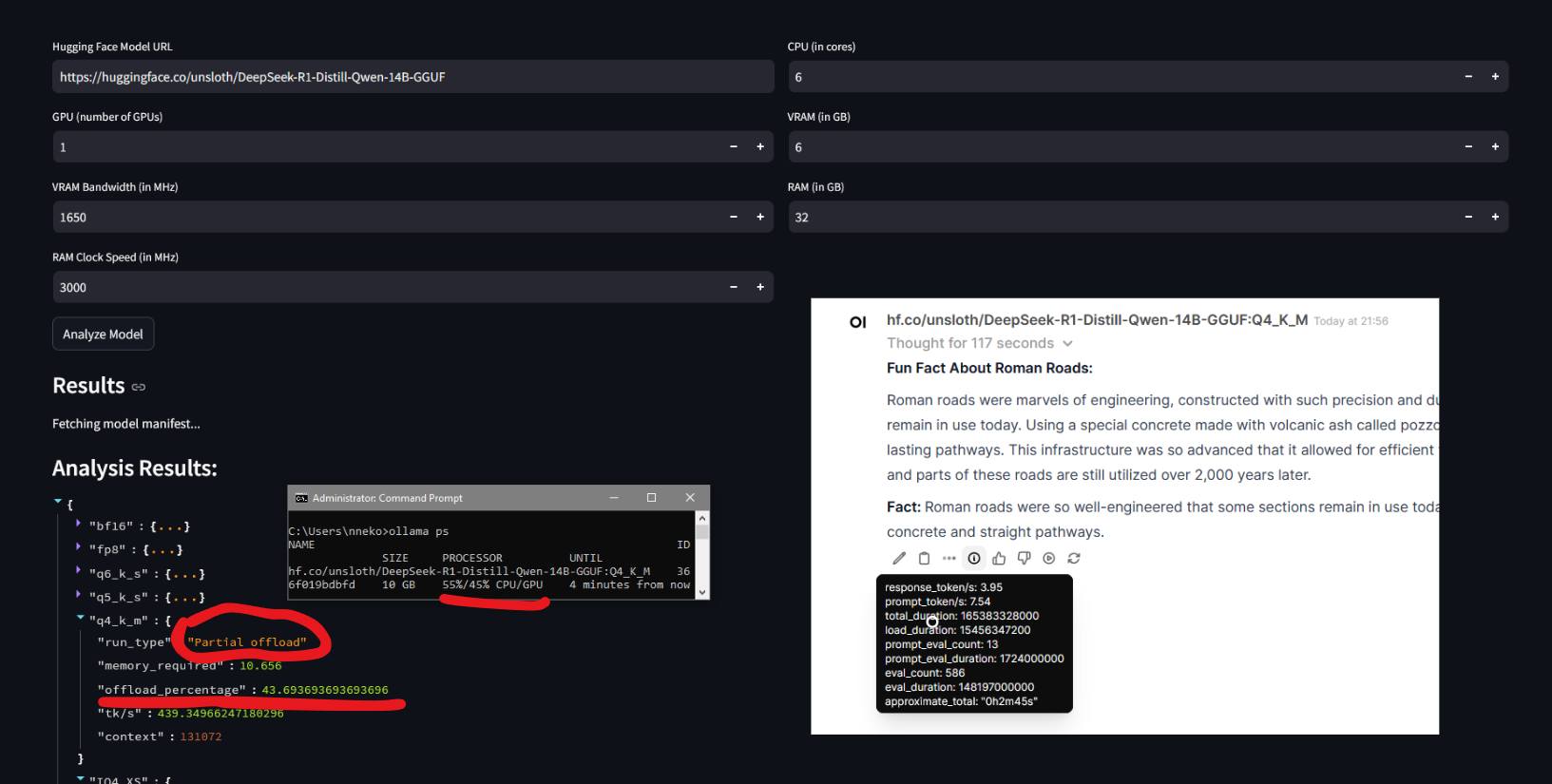
Optimizing Hardware Resource Allocation
Efficient resource allocation significantly impacts performance:
- Select models where partial offloading doesn’t disproportionately favor CPU usage over GPU
- Models that can run entirely in VRAM generally deliver superior performance
- Balanced resource allocation ensures reasonable token generation speeds (tokens per second)
- Poorly matched models may result in excessive response generation times (5-10 minutes)
Fine-tuning for Specialized Applications
For optimal performance in specific domains:
- Consider fine-tuned models for specialized applications
- Domain-specific fine-tuning can significantly enhance performance for particular use cases
- Evaluate whether the performance improvements justify the additional resources required for fine-tuning
Conclusion
Selecting the right AI model for local deployment requires balancing multiple factors including format, quantization level, model size, and hardware resource allocation. By carefully considering these elements and utilizing resources like Can I Run This LLM, users can achieve optimal performance while working within their hardware constraints.
